-
MongoDB Oplog 와 Journaling 차이MongoDB 2021. 4. 28. 14:04반응형
MongoDB에서 Oplog와 Journaling이라는 개념이 있습니다.
어느날 엇?! 이게 뭐였더라 둘다 sync를 맞춰주는 녀석이었던 같은데 확실하게 어떤 차이가있지?? 라고 헷갈리기 시작해서 정리하게되었습니다.
1. Oplog (operations log)
정확한 이름은 Replica Set Oplog입니다. 네이밍에서 느껴지듯이 이 개념은 레플리카에 속하는 개념입니다.
Oplog는 Replica set의 데이터를 동기화를 위해 내부에서 발생하는 모든 동작의 로그를 기록한 것 입니다.
Replica set의 개념을 제대로 모르는 분들을 위해 간략하게 설명!
MongoDB는 HA(High Availability)를 위해 클러스터를 구축하는 개념이 Replica set 입니다. 이 클러스터를 구축하기 위해서 각각의 데이터베이스 서버들은 Primary, Secondary, Arbiter 라는 역할을 가질 수 있으며 P-S-S, P-S-A 구조를 통해 레플리카셋을 구축할 수 있습니다.Q.왜 동기화를 위해 로그를 남겨? 그냥 요청들어오면 동시에 반영하면 되는거 아니야?
Secondary는 Primary가 문제가 발생했을때를 위해 존재하는 대타라고 볼 수 있습니다.
때문에 데이터의 변경을 처리할 수 있는 유일한 멤버는 Primary 이며 Primary는 변경사항을 Oplog에 기록하여 나머지 멤버들이 Primary와 동기화를 비동기적으로 진행할 수 있도록 하는 것 입니다.
Oplog는 capped collection이라는 특수한 컬렉션에 저장됩니다.
capped collection은 고정된 크기를 가지며 해당 크기가 꽉차면 오래된 순으로 자동으로 삭제가되는 로그성 데이터를 저장하기 편한 컬렉션 입니다.
하지만 MongoDB 4.0부터는 일반적인 capped 컬렉션과는 달리 용량을 초과해도 majority commit point 이 삭제되는것을 방지할 수 있습니다,
즉, 용량을 초과해도 처리가 안된것들은 삭제가되지 않습니다.
OS에 따라 기본적으로 할당되는 사이즈가 다르며 사이즈를 변경할 수 있습니다.
(docs.mongodb.com/manual/tutorial/change-oplog-size/)
Oplog는 아래의 명령어를 통해 직접 확인해볼 수 있습니다.
db.getCollection("oplog.rs").find({})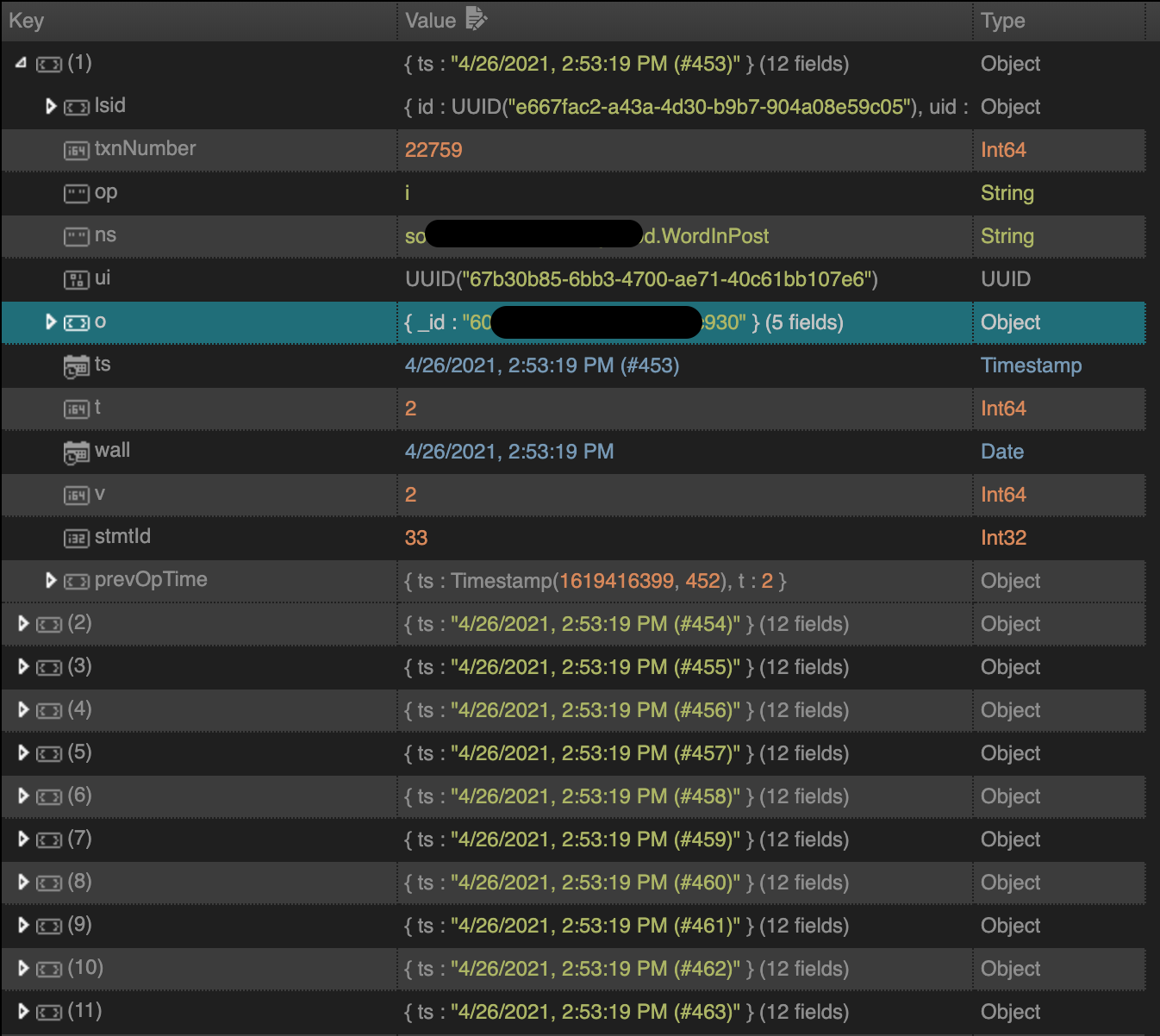
그리고 현재 어디까지 동기화를 진행했으며 얼마나 지연이 발생하는지 파악하기 위해서 아래의 명령어를 활용하면됩니다.
db.printSecondaryReplicationInfo() // source: 52.78.xx.3:xxxxx // syncedTo: Wed Apr 28 2021 14:12:17 GMT+0900 (Korean Standard Time) // 10 secs (0 hrs) behind the primary추가로 Oplog를 이용해서 Prometheus + Grafana를 이용하면 현재 동기화가 얼마나 밀리는지 Lag을 시각화할 수 도 있습니다.
모니터링에 좋은 요소이므로 추천드립니다.

2. Jouranling
실패시 복구상황에서 사용되는 journal 파일에 로깅하는 행위를 말합니다.
journal이란? hard shutdown시에 복구를 위해서 사용되는 sequential, binary transaction log 입니다.
MongoDB의 Storage 엔진인 WiredTiger는 쓰기 작업(삽입, 수정)이 발생할때마다 하나의 journal record를 생성하며 journal에는 해당 쿼리와 인덱스 변경에대한 내용이 포함되어있습니다.
이 파일은 config에서 설정한 data 경로의 journal 폴더에 작성되며 write-ahead log이므로 core data에 반영되기전에 먼저 로깅되게됩니다.
Q. 그러면 복구상황에서 어떻게 journal 파일이 이용되는건가요?
WiredTiger의 journal은 checkpoint 사이의 모든 데이터 작업 사항을 유지합니다. 때문에 재해상황(hard shutdown)시에 journal 파일을 사용하여 마지막 체크포인트 이후의 모든 변경사항을 재실행하여 영속성을 보장합니다.
Q. check point가 무엇인가요?
checkpoint는 journal 과 데이터파일이 동기화되는 시점을 의미합니다.
3.6버전부터 60초 간격으로 check point가 생성됩니다. 주기적으로 동작하기 때문에 새로운 check point가 생성되며 그 이전 journal은 삭제되거나 덮어쓰며 관리를 합니다.
Q. 왜 journal과 데이터파일을 동기화 시켜야하나요? journal에 말고 바로 데이터파일에 반영하면되잖아요?.
WiredTiger는 MVCC (MultiVersion Concurrency Control)을 사용하여 많은 이점을 가져가고있습니다.
여기서 MVCC를 다 설명하진 않겠습니다. 하나의 다큐먼트가 작업이 발생할때마다 원본이 아닌 복사본을 만들어서 버전 관리를 한다고 이해하시면 됩니다.
때문에 매번 변경사항을 바로 디스크에 반영하지 않고 메모리에서 관리하다가 특정시점에 스냅샷형태로 한번에 디스크에 반영하는 동작방식을 사용합니다.
docs.mongodb.com/manual/core/replica-set-oplog/
Replica Set Oplog — MongoDB Manual
The oplog (operations log) is a special capped collection that keeps a rolling record of all operations that modify the data stored in your databases. Changed in version 4.0: Starting in MongoDB 4.0, unlike other capped collections, the oplog can grow past
docs.mongodb.com
docs.mongodb.com/manual/core/journaling/
Journaling — MongoDB Manual
In between write operations, while the journal records remain in the WiredTiger buffers, updates can be lost following a hard shutdown of mongod.
docs.mongodb.com
반응형'MongoDB' 카테고리의 다른 글
MongoDB Shard 개수에 따른 퍼포먼스 확인하기 (2) 2021.04.26 MongoDB 초간단 log 관리하기 (0) 2021.04.26 MongoDB 스키마 디자인 패턴 (0) 2020.08.20